
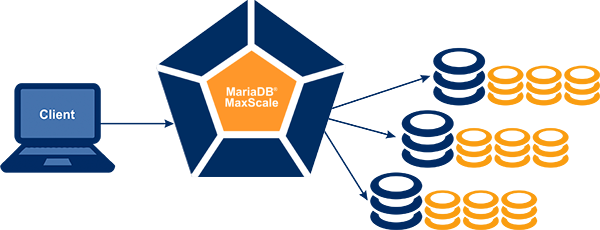
maxscale 은 DB 프록시로 로드밸런서의 역할을 한다. 이거는 mysql 과는 상이한 프로그램으로 플러그인이라늗가에 포함되지 않고 DB 와 완전히 별개의 프로그램으로 동작한다. 전 글을 참고해도 좋을 것 같다.
maxscale 상속 과정
maxscale 은 master 로 write 쿼리가 들어가고 동기화 설정으로 인해 slave 까지 해당 변화가 넘어간다. (이때 주의해야 할 점은 maxscale 은 mysql 에 소속되어 있지 않기 때문에, 동기화 작업은 DB 단에서 이루어진다!) read 쿼리는 slave 로 넘겨주거나 분산해서 받거나 하는 식으로 너무 많을 경우 분산해서 받을 수 있다. maxscale 은 master 가 있고 master candidate 를 설정할 수 있는데 이 후보들은 master 가 죽은 경우 master 를 이어 받아서 master 가 하던 역할을 그대로 수행할 수 있다.
write 쿼리 스트레스 테스트
그렇다면 이 전환 과정에서 write 쿼리가 거대하게 들어온다면? 어떻게 될것인가? 해당 부분의 쿼리는 잘 처리가 될 것인가? 에 대한 의문이 들어서 테스트를 진행하게 되었다. 결론적으로 말하자면 완전하지는 않다. 해당 테스트는 VirtualBox 와 ubuntu live 20.04 LTS 로 진행을 하였고, 4중화되어 있는 서버에 테스트를 진행하였다. 초당 write 를 쏜 횟수는 10회 - 50회 정도 진행하였다. 당연하게도 쿼리는 DB 프록시인 maxscale 포트로 쐈다.(mysql 에 직접 write 쿼리를 쏘면 그 순간 동기화가 깨진다) 테스트는 결론적으로 말하자면 종료되었던 master 가 다시 켜지는 시점에깨진다.
동기화가 깨지는 시나리오
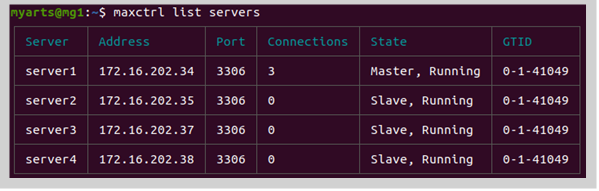
1번이 master 였고 원래 write 쿼리를 받고 있었다. 근데 1번이 종료가 된다면 master candidate 인 2번이 master 로 전환하는데 10초간의 시간이 걸린다. 그 사이에 쿼리는 session time out 이 나며 전송되는데 실패한다. 10초가 지나고 server 2 가 master 로 올라오면 그때부터는 server2 가 write 를 잘 받는다. 그렇지만 server 1 이 다시 켜진다면? 이때 server 1 에 write 이 들어가면서 동기화가 깨진다. 동기화가 깨지는 원인은 자세히는 모르겠지만, server 1이 slave 로 세팅되기 전에 master 로 인식된 쿼리가 캐시되어 남아있던게 처리되며 mysql 에 직접 write 를 쏴서 그런게 아닌가... 라는 의심을 한다. 아 read 쿼리로는 아무 문제가 없다. read 쿼리는 어디에 쏴지든 상관이 없기 때문이다.
이 문제를 해결하기 위해 관리 서버에 DB 동기화를 할 수 있는 UI 를 추가하거나, k8s 를 도입하거나 하는 방식으로 진행을 해야 할 것 같다. 클라우드에 대한 좋은 실험이었던 것 같다.
'CS > DB' 카테고리의 다른 글
| [DB] Maxscale 이중화 방법(ubuntu live) (0) | 2024.08.02 |
|---|---|
| [캐글] regression 시각화 (kaggle store-sales-time-series-forecasting_3) (0) | 2022.10.23 |
| [캐글] 중복된 데이터 병합하기 (kaggle store-sales-time-series-forecasting_2) (0) | 2022.10.23 |
| [캐글] 파이썬 CSV 데이터 확인하는 2가지 방법 (kaggle store-sales-time-series-forecasting_1) (0) | 2022.10.19 |
| [MySQL] First normalization, 다대다, 연결 테이블 (0) | 2022.02.05 |