
아스키코드
아스키코드는 '한 문자'를 1byte 즉 7bit 에 담아내는 규칙이다.
아스키코드는 ASCII로 American Standard Code for Information Interchange 의 약자이다.
이를테면 53도 두 문자기에 0x35 0x32 로 표현이 된다.
문자를 나타내는 규칙에 아스키코드만 있는건 아니다.
이를테면 Base64는 6bit 를 한문자에 담아낸 규칙이고, bytetohex는 4bit 를 한 문자에 담아내는 규칙이다.
아래에서 설명할 확장아스키코드는 한 문자를 8bit 에 담아내는 규칙이고,
unicode 는 2byte 즉 16bit 를 한 문자에 담아내는 규칙이다.
C/C++에서 char 가 1byte(8bit) 인 것으로 기억하면 된다.
c언어는 언어의 특성상 메모리 접근이 용이하다. mid-level 언어라서 다른 상위레벨 언어보다 접근이 쉽다.
아스키코드는 ASCII로 American Standard Code for Information Interchange 의 약자이다.
ASCII CODE 는 0 - 127까지 키보드의 모든 숫자를 넣어두었다.
즉 7bit에 해당하는 전압으로 모든 키보드를 동작시킬 수 있는 것이다.

아스키코드의 0번인 0x00인 NUL은 문자열의 끝을 나타낸다.
7번 0x07은 경고음을 만든다.
10번 0x0A는 엔터키(줄바꿈)과 같다.
27번 0x1B는 ESC 이다.
32번 0x20는 스페이스키(공백)과 같다.
확장 ASCII CODE는 유럽어와 특수문자까지도 포함하였다
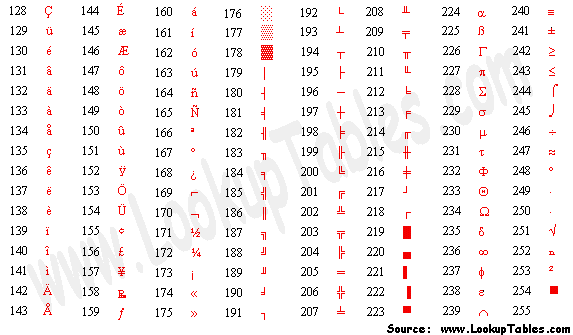
단순히 타자를 치는 작업에도 이것은 적용된다.
문자를 입력하면 이는 이진수로 바뀌어 인식되고,
컴퓨터는 아스키코드 테이블을 뒤져 해당하는 문자를 찾고
이를 모니터에 그려주는 것이다.
이를테면 B를 누른다면
컴퓨터엔 1000010에 해당하는 전압이 전달되고
이 비트값은 0x42로 변환되며
이 디지털신호는 데이터버스로 컴퓨터에 전달되고 화면에 띄워진다.
이 신호는 개발자의 요청에 따라 B로 표시될 수도 있고, 0x42로 표시될수도 있고, 66으로 표시될 수도 있다.
유니코드

아스키코드에서 발전한 기능으론 Unicode 가 있으며, 아스키코드와 달리 문자당 2byte 에 담긴다.
일례로 C/C++에선 char 가 1byte 이지만 Java에선 char 가 2byte 인 이유는 자바는 유니코드 규칙을 따르기 때문이다.
유니코드는 UTF-8 과 함께 많이 쓰여 혼동이 될 수 있다.
유니코드는 문자와 byte 가 매핑된 테이블이고 UTF-8 은 문자를 byte 로 인코딩하는 방식을 의미한다.
아스키코드는 테이블과 인코딩하는 방식을 모두 나타내지만
유니코드부터는 인코딩하는 방식이 여러가지로 분화되기 시작하면서 그 의미가 테이블만을 가리키도록 한정되었다.
'CS' 카테고리의 다른 글
| [네트워크] HTTP Header 구조 (3) | 2022.12.27 |
|---|---|
| [네트워크] HTTPS 정의, HTTPS 요청/응답 방식 (0) | 2022.12.27 |
| [네트워크] 허브/스위치/라우터/공유기 (0) | 2022.12.21 |
| [CS] OSI 7계층, TCP 4계층 차이점 (0) | 2022.12.21 |
| [네트워크] LAN/MAN/WAN, IP추적이 가능한가? (0) | 2022.12.21 |